前言
我目前在维护一款功能强大的开源创意画板。这个画板集成了很多有意思的画笔和辅助绘画功能,可以让用户体验到全新的绘画效果。无论是在移动端还是PC端,都能享受到较好的交互体验和效果展示。
在本文中,我将详细讲解如何结合 Transformers.js 实现去除背景和图像标记分割功能。大概效果如下

访问链接: https://songlh.top/paint-board/
Github: https://github.com/LHRUN/paint-board 欢迎Star⭐️
Transformers.js 介绍
Transformers.js 是一个功能强大的 JavaScript 库,基于 Hugging Face 的 Transformers, 可以直接在浏览器中运行,而无需依赖服务器端计算. 这就意味着通过它, 你可以直接在本地运行模型, 能大幅提升效率和降低部署和维护的成本.
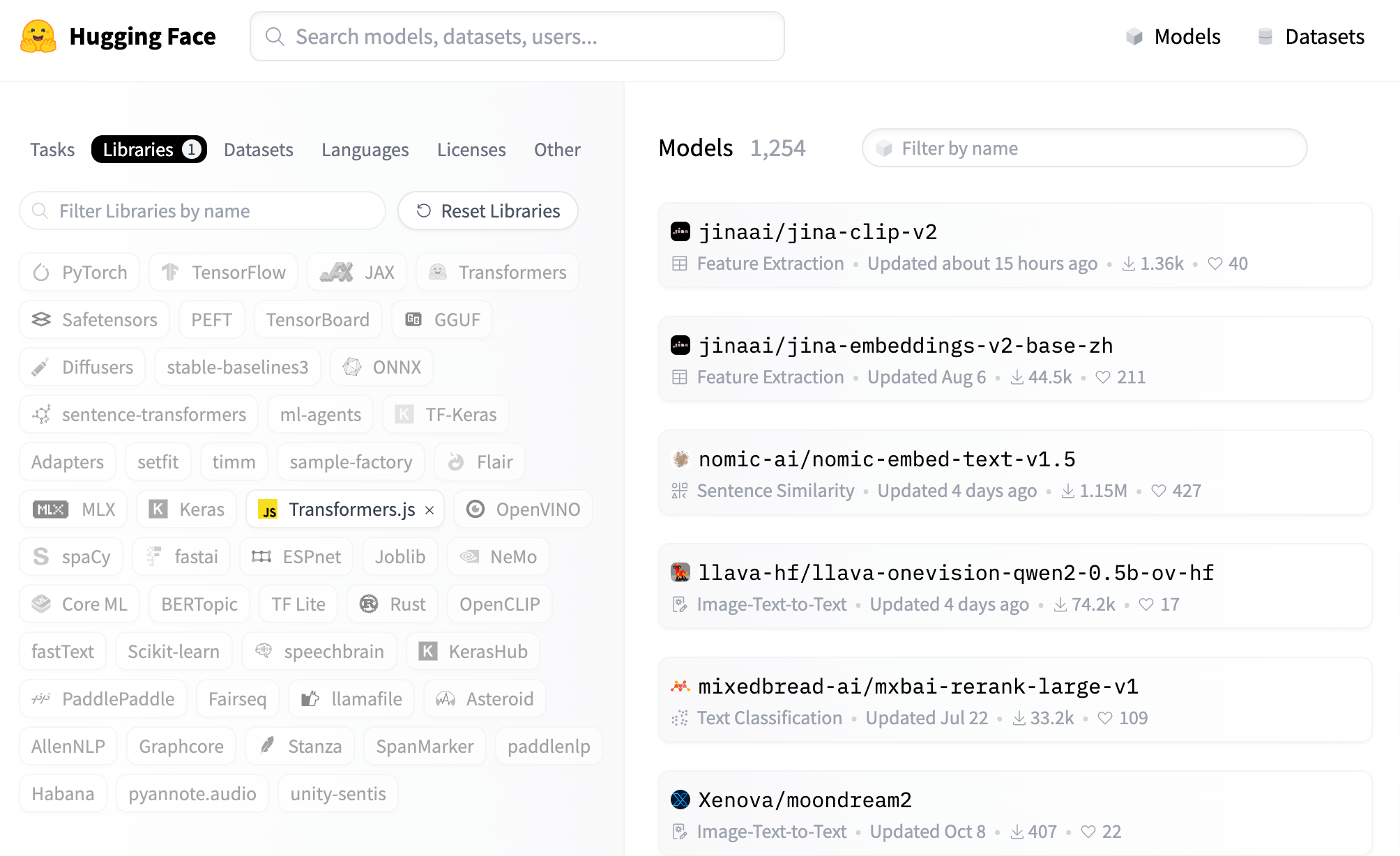
目前 Transformers.js 已经在 Hugging Face 上提供了 1000+ 模型, 覆盖了各个领域, 能满足你的大多数需求, 如图像处理、文本生成、翻译、情感分析等任务处理, 你都可以通过 Transformers.js 轻松实现. 搜索模型方式如下:
目前 Transformers.js 的大版本已更新到了 V3, 增加了很多大功能, 具体可以看 Transformers.js v3: WebGPU Support, New Models & Tasks, and More….
我本篇文章加的这两个功能都是用到了 V3 才有的 WebGpu 支持, 极大的提升了处理速度, 目前的解析都是在毫秒级. 但是需要注意的是, 目前支持 WebGPU 的浏览器不太多, 因此建议使用最新版谷歌进行访问
功能一: 实现去除背景
去除背景我是使用的 Xenova/modnet 模型, 效果如下

处理逻辑可分三步
- 初始化状态, 并加载模型和处理器
- 点击按钮, 加载图像并进行预处理, 然后通过模型生成透明蒙层, 最后根据透明蒙层和你的原始图像通过 canvas 进行像素对比生成一个去除背景的图像
- 界面展示, 这个以你自己的设计任意发挥, 不用以我的为准. 现在比较流行的就是通过一个边界线来动态展示去除背景前后的对比效果
大概代码逻辑如下, React + TS , 具体可以查看我项目的源码, 源码位置 src/components/boardOperation/uploadImage/index.tsx
import { useState, FC, useRef, useEffect, useMemo } from 'react'
import {
env,
AutoModel,
AutoProcessor,
RawImage,
PreTrainedModel,
Processor
} from '@huggingface/transformers'
const REMOVE_BACKGROUND_STATUS = {
LOADING: 0, // 模型加载中
NO_SUPPORT_WEBGPU: 1, // 不支持
LOAD_ERROR: 2, // 加载失败
LOAD_SUCCESS: 3, // 加载成功
PROCESSING: 4, // 处理中
PROCESSING_SUCCESS: 5 // 处理成功
}
type RemoveBackgroundStatusType =
(typeof REMOVE_BACKGROUND_STATUS)[keyof typeof REMOVE_BACKGROUND_STATUS]
const UploadImage: FC<{ url: string }> = ({ url }) => {
const [removeBackgroundStatus, setRemoveBackgroundStatus] =
useState<RemoveBackgroundStatusType>()
const [processedImage, setProcessedImage] = useState('')
const modelRef = useRef<PreTrainedModel>()
const processorRef = useRef<Processor>()
const removeBackgroundBtnTip = useMemo(() => {
switch (removeBackgroundStatus) {
case REMOVE_BACKGROUND_STATUS.LOADING:
return '去除背景功能加载中'
case REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU:
return '本浏览器不支持WebGPU, 要使用去除背景功能请使用最新版谷歌浏览器'
case REMOVE_BACKGROUND_STATUS.LOAD_ERROR:
return '去除背景功能加载失败'
case REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS:
return '去除背景功能加载成功'
case REMOVE_BACKGROUND_STATUS.PROCESSING:
return '去除背景处理中'
case REMOVE_BACKGROUND_STATUS.PROCESSING_SUCCESS:
return '去除背景处理成功'
default:
return ''
}
}, [removeBackgroundStatus])
useEffect(() => {
;(async () => {
try {
if (removeBackgroundStatus === REMOVE_BACKGROUND_STATUS.LOADING) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOADING)
// 检查 WebGPU 支持
if (!navigator?.gpu) {
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU)
return
}
const model_id = 'Xenova/modnet'
if (env.backends.onnx.wasm) {
env.backends.onnx.wasm.proxy = false
}
// 加载模型和处理器
modelRef.current ??= await AutoModel.from_pretrained(model_id, {
device: 'webgpu'
})
processorRef.current ??= await AutoProcessor.from_pretrained(model_id)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS)
} catch (err) {
console.log('err', err)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_ERROR)
}
})()
}, [])
const processImages = async () => {
const model = modelRef.current
const processor = processorRef.current
if (!model || !processor) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.PROCESSING)
// 加载图像
const img = await RawImage.fromURL(url)
// 预处理图像
const { pixel_values } = await processor(img)
// 生成图像蒙版
const { output } = await model({ input: pixel_values })
const maskData = (
await RawImage.fromTensor(output[0].mul(255).to('uint8')).resize(
img.width,
img.height
)
).data
// 创建一个新的 canvas
const canvas = document.createElement('canvas')
canvas.width = img.width
canvas.height = img.height
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D
// 绘制原始图像
ctx.drawImage(img.toCanvas(), 0, 0)
// 更新蒙版区域
const pixelData = ctx.getImageData(0, 0, img.width, img.height)
for (let i = 0; i < maskData.length; ++i) {
pixelData.data[4 * i + 3] = maskData[i]
}
ctx.putImageData(pixelData, 0, 0)
// 保存新图片
setProcessedImage(canvas.toDataURL('image/png'))
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.PROCESSING_SUCCESS)
}
// 界面展示
return (
<div className="card shadow-xl">
<button
className={`btn btn-primary btn-sm ${
![
REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS,
REMOVE_BACKGROUND_STATUS.PROCESSING_SUCCESS,
undefined
].includes(removeBackgroundStatus)
? 'btn-disabled'
: ''
}`}
onClick={processImages}
>
去除背景
</button>
<div className="text-xs text-base-content mt-2 flex">
{removeBackgroundBtnTip}
</div>
<div className="relative mt-4 border border-base-content border-dashed rounded-lg overflow-hidden">
<img
className={`w-[50vw] max-w-[400px] h-[50vh] max-h-[400px] object-contain`}
src={url}
/>
{processedImage && (
<img
className={`w-full h-full absolute top-0 left-0 z-[2] object-contain`}
src={processedImage}
/>
)}
</div>
</div>
)
}
export default UploadImage功能二: 实现图像标记分割
图像标记分割我是通过 Xenova/slimsam-77-uniform 模型实现. 具体效果如下, 在你加载成功后可以点击图片, 然后根据你点击的坐标生成分割效果.
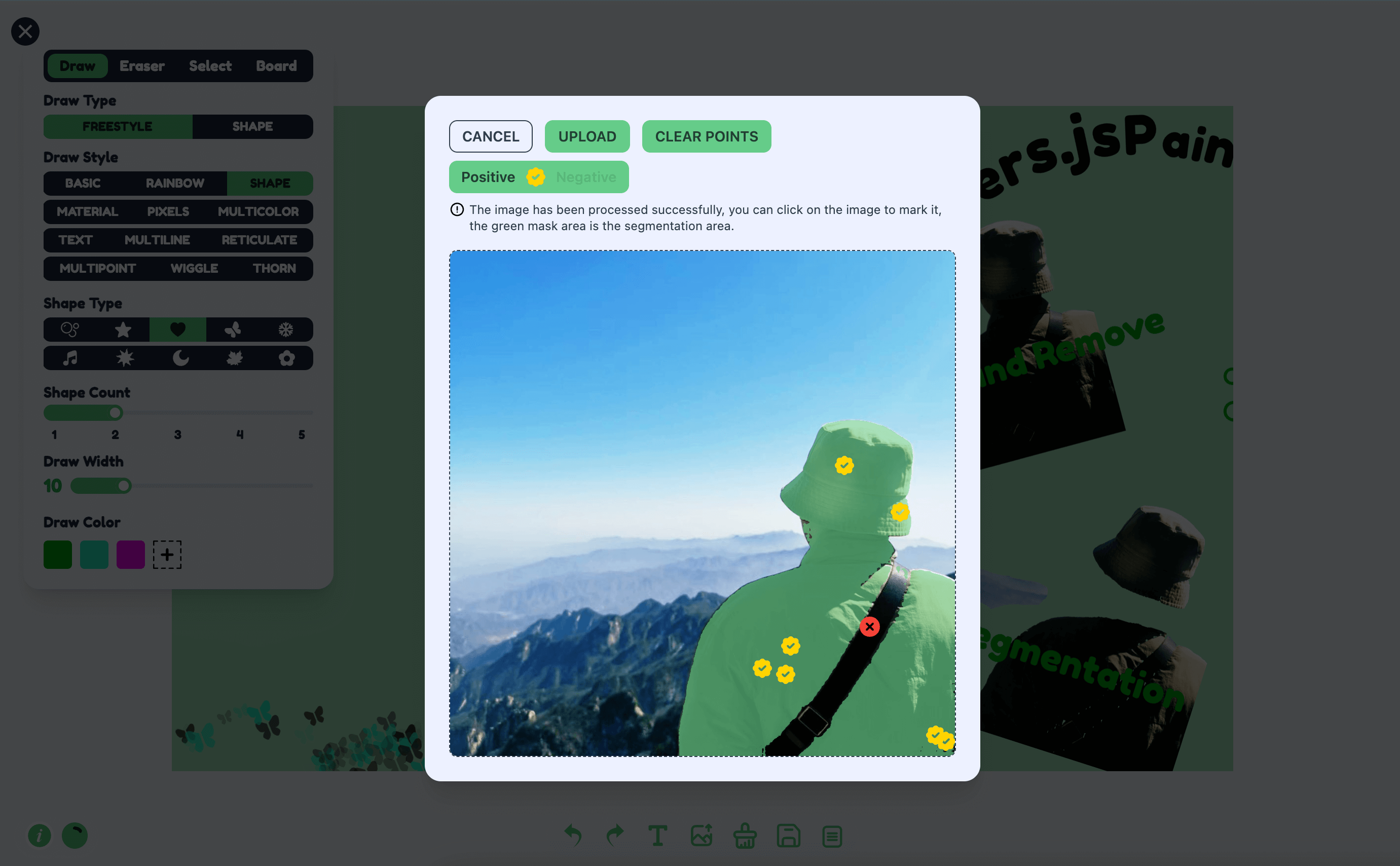
处理逻辑可分五步
- 初始化状态, 并加载模型和处理器
- 获取图像并加载, 然后保存图像加载数据和嵌入数据
- 监听图像点击事件, 记录点击数据, 分为正标记和负标记, 每次点击后根据点击数据进行解码生成蒙层数据, 然后根据蒙层数据绘制分割效果
- 界面展示, 这个以你自己的设计任意发挥, 不用以我的为准
- 点击保存图片, 根据蒙层像素数据, 匹配出原始图像的数据, 然后通过 canvas 绘制导出
大概代码逻辑如下, React + TS , 具体可以查看我项目的源码, 源码位置 src/components/boardOperation/uploadImage/imageSegmentation.tsx
import { useState, useRef, useEffect, useMemo, MouseEvent, FC } from 'react'
import {
SamModel,
AutoProcessor,
RawImage,
PreTrainedModel,
Processor,
Tensor,
SamImageProcessorResult
} from '@huggingface/transformers'
import LoadingIcon from '@/components/icons/loading.svg?react'
import PositiveIcon from '@/components/icons/boardOperation/image-segmentation-positive.svg?react'
import NegativeIcon from '@/components/icons/boardOperation/image-segmentation-negative.svg?react'
interface MarkPoint {
position: number[]
label: number
}
// 处理状态
const SEGMENTATION_STATUS = {
LOADING: 0, // 模型加载中
NO_SUPPORT_WEBGPU: 1, // 不支持 WebGPU
LOAD_ERROR: 2, // 模型加载失败
LOAD_SUCCESS: 3, // 模型加载成功
PROCESSING: 4, // 图像处理中
PROCESSING_SUCCESS: 5 // 图像处理成功
}
type SegmentationStatusType =
(typeof SEGMENTATION_STATUS)[keyof typeof SEGMENTATION_STATUS]
const ImageSegmentation: FC<{ url: string }> = ({ url }) => {
const [markPoints, setMarkPoints] = useState<MarkPoint[]>([])
const [segmentationStatus, setSegmentationStatus] =
useState<SegmentationStatusType>()
const [pointStatus, setPointStatus] = useState<boolean>(true)
const maskCanvasRef = useRef<HTMLCanvasElement>(null) // 分割蒙版
const modelRef = useRef<PreTrainedModel>() // 模型
const processorRef = useRef<Processor>() // 处理器
const imageInputRef = useRef<RawImage>() // 原始图像
const imageProcessed = useRef<SamImageProcessorResult>() // 处理过的图像
const imageEmbeddings = useRef<Tensor>() // 嵌入数据
const segmentationTip = useMemo(() => {
switch (segmentationStatus) {
case SEGMENTATION_STATUS.LOADING:
return '图像分割功能加载中'
case SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU:
return '本浏览器不支持WebGPU, 要使用图像分割功能请使用最新版谷歌浏览器'
case SEGMENTATION_STATUS.LOAD_ERROR:
return '图像分割功能加载失败'
case SEGMENTATION_STATUS.LOAD_SUCCESS:
return '图像分割功能加载成功'
case SEGMENTATION_STATUS.PROCESSING:
return '处理图像中'
case SEGMENTATION_STATUS.PROCESSING_SUCCESS:
return '图像处理成功, 可点击图像进行标记, 绿色蒙层区域就是分割区域'
default:
return ''
}
}, [segmentationStatus])
// 1. 加载模型和处理器
useEffect(() => {
;(async () => {
try {
if (segmentationStatus === SEGMENTATION_STATUS.LOADING) {
return
}
setSegmentationStatus(SEGMENTATION_STATUS.LOADING)
if (!navigator?.gpu) {
setSegmentationStatus(SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU)
return
}
const model_id = 'Xenova/slimsam-77-uniform'
modelRef.current ??= await SamModel.from_pretrained(model_id, {
dtype: 'fp16', // or "fp32"
device: 'webgpu'
})
processorRef.current ??= await AutoProcessor.from_pretrained(model_id)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_SUCCESS)
} catch (err) {
console.log('err', err)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_ERROR)
}
})()
}, [])
// 2. 处理图像
useEffect(() => {
;(async () => {
try {
if (
!modelRef.current ||
!processorRef.current ||
!url ||
segmentationStatus === SEGMENTATION_STATUS.PROCESSING
) {
return
}
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING)
clearPoints()
imageInputRef.current = await RawImage.fromURL(url)
imageProcessed.current = await processorRef.current(
imageInputRef.current
)
imageEmbeddings.current = await (
modelRef.current as any
).get_image_embeddings(imageProcessed.current)
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING_SUCCESS)
} catch (err) {
console.log('err', err)
}
})()
}, [url, modelRef.current, processorRef.current])
// 更新蒙层效果
function updateMaskOverlay(mask: RawImage, scores: Float32Array) {
const maskCanvas = maskCanvasRef.current
if (!maskCanvas) {
return
}
const maskContext = maskCanvas.getContext('2d') as CanvasRenderingContext2D
// 更新 canvas 尺寸
if (maskCanvas.width !== mask.width || maskCanvas.height !== mask.height) {
maskCanvas.width = mask.width
maskCanvas.height = mask.height
}
// 分配蒙层区域
const imageData = maskContext.createImageData(
maskCanvas.width,
maskCanvas.height
)
const numMasks = scores.length // 3
let bestIndex = 0
for (let i = 1; i < numMasks; ++i) {
if (scores[i] > scores[bestIndex]) {
bestIndex = i
}
}
// 填充蒙层颜色
const pixelData = imageData.data
for (let i = 0; i < pixelData.length; ++i) {
if (mask.data[numMasks * i + bestIndex] === 1) {
const offset = 4 * i
pixelData[offset] = 101 // r
pixelData[offset + 1] = 204 // g
pixelData[offset + 2] = 138 // b
pixelData[offset + 3] = 255 // a
}
}
// 绘制
maskContext.putImageData(imageData, 0, 0)
}
// 3. 根据点击数据进行解码
const decode = async (markPoints: MarkPoint[]) => {
if (
!modelRef.current ||
!imageEmbeddings.current ||
!processorRef.current ||
!imageProcessed.current
) {
return
}
// 没有点击数据直接清除分割效果
if (!markPoints.length && maskCanvasRef.current) {
const maskContext = maskCanvasRef.current.getContext(
'2d'
) as CanvasRenderingContext2D
maskContext.clearRect(
0,
0,
maskCanvasRef.current.width,
maskCanvasRef.current.height
)
return
}
// 生成解码所需数据
const reshaped = imageProcessed.current.reshaped_input_sizes[0]
const points = markPoints
.map((x) => [x.position[0] * reshaped[1], x.position[1] * reshaped[0]])
.flat(Infinity)
const labels = markPoints.map((x) => BigInt(x.label)).flat(Infinity)
const num_points = markPoints.length
const input_points = new Tensor('float32', points, [1, 1, num_points, 2])
const input_labels = new Tensor('int64', labels, [1, 1, num_points])
// 生成蒙版
const { pred_masks, iou_scores } = await modelRef.current({
...imageEmbeddings.current,
input_points,
input_labels
})
// 处理蒙版
const masks = await (processorRef.current as any).post_process_masks(
pred_masks,
imageProcessed.current.original_sizes,
imageProcessed.current.reshaped_input_sizes
)
updateMaskOverlay(RawImage.fromTensor(masks[0][0]), iou_scores.data)
}
const clamp = (x: number, min = 0, max = 1) => {
return Math.max(Math.min(x, max), min)
}
// 点击图像
const clickImage = (e: MouseEvent) => {
if (segmentationStatus !== SEGMENTATION_STATUS.PROCESSING_SUCCESS) {
return
}
const { clientX, clientY, currentTarget } = e
const { left, top } = currentTarget.getBoundingClientRect()
const x = clamp(
(clientX - left + currentTarget.scrollLeft) / currentTarget.scrollWidth
)
const y = clamp(
(clientY - top + currentTarget.scrollTop) / currentTarget.scrollHeight
)
const existingPointIndex = markPoints.findIndex(
(point) =>
Math.abs(point.position[0] - x) < 0.01 &&
Math.abs(point.position[1] - y) < 0.01 &&
point.label === (pointStatus ? 1 : 0)
)
const newPoints = [...markPoints]
if (existingPointIndex !== -1) {
// 如果当前点击区域存在标记, 则进行删除
newPoints.splice(existingPointIndex, 1)
} else {
newPoints.push({
position: [x, y],
label: pointStatus ? 1 : 0
})
}
setMarkPoints(newPoints)
decode(newPoints)
}
const clearPoints = () => {
setMarkPoints([])
decode([])
}
return (
<div className="card shadow-xl overflow-auto">
<div className="flex items-center gap-x-3">
<button className="btn btn-primary btn-sm" onClick={clearPoints}>
清除标记点
</button>
<button
className="btn btn-primary btn-sm"
onClick={() => setPointStatus(true)}
>
{pointStatus ? '正标记' : '负标记'}
</button>
</div>
<div className="text-xs text-base-content mt-2">{segmentationTip}</div>
<div
id="test-image-container"
className="relative mt-4 border border-base-content border-dashed rounded-lg h-[60vh] max-h-[500px] w-fit max-w-[60vw] overflow-x-auto overflow-y-hidden"
onClick={clickImage}
>
{segmentationStatus !== SEGMENTATION_STATUS.PROCESSING_SUCCESS && (
<div className="absolute z-[3] top-0 left-0 w-full h-full bg-slate-400 bg-opacity-70 flex justify-center items-center">
<LoadingIcon className="animate-spin" />
</div>
)}
<div className="h-full w-max relative overflow-hidden">
<img className="h-full max-w-none" src={url} />
<canvas
ref={maskCanvasRef}
className="absolute top-0 left-0 h-full w-full z-[1] opacity-60"
></canvas>
{markPoints.map((point, index) => {
switch (point.label) {
case 1:
return (
<PositiveIcon
key={index}
className="w-[24px] h-[24px] absolute z-[2] -ml-[13px] -mt-[14px] fill-[#FFD401]"
style={{
top: `${point.position[1] * 100}%`,
left: `${point.position[0] * 100}%`
}}
/>
)
case 0:
return (
<NegativeIcon
key={index}
className="w-[24px] h-[24px] absolute z-[2] -ml-[13px] -mt-[14px] fill-[#F44237]"
style={{
top: `${point.position[1] * 100}%`,
left: `${point.position[0] * 100}%`
}}
/>
)
default:
return null
}
})}
</div>
</div>
</div>
)
}
export default ImageSegmentation
总结
感谢你的阅读。以上就是本文的全部内容,希望这篇文章对你有所帮助,欢迎点赞和 Star 。如果有任何问题,欢迎在评论区进行讨论